Playwright Web Scraping - How to Extract Data from Websites
We call the action of extracting data from web pages web scraping. Scraping is useful for a variety of use cases:
- In testing and monitoring, asserting against the state of one or more elements on a page
- In general, gathering data for a variety of different purposes
Scraping element attributes & properties
Below is an example running against our test site, getting and printing out the href attribute of the first a element on the homepage. That just happens to be our logo, which links right back to our homepage, and therefore will have an href value equal to the URL we navigate to using page.goto():
const { chromium } = require('playwright')
;(async () => {
const browser = await chromium.launch()
const page = await browser.newPage()
await page.goto('https://danube-web.shop/')
const url = await page.$eval('a', (el) => el.href)
console.log(url)
await browser.close()
})()
As an alternative, it is also possible to retrieve an ElementHandle and then retrieve a property value from it. Following is an example printing the href value of the first a element of our homepage:
const { chromium } = require('playwright')
;(async () => {
const browser = await chromium.launch()
const page = await browser.newPage()
await page.goto('https://danube-web.shop/')
const element = await page.$('a')
const href = await element.evaluate((node) => node.href)
console.log(href)
await browser.close()
})()
The
innerTextproperty is often used in tests to assert that some element on the page contains the expected text.
Scraping lists of elements
Scraping element lists is just as easy. For example, let’s grab the innerText of each product category shown on the homepage:
const { chromium } = require('playwright')
;(async () => {
const browser = await chromium.launch()
const page = await browser.newPage()
await page.goto('https://danube-web.shop/')
const categories = await page.$$eval('li a', (nodes) =>
nodes.map((n) => n.innerText)
)
console.log(categories)
await browser.close()
})()
Scraping images
Scraping images from a page is also possible. For example, we can easily get the logo of our test website and save it as a file:
const { chromium } = require('playwright')
const axios = require('axios')
const fs = require('fs')
;(async () => {
const browser = await chromium.launch()
const page = await browser.newPage()
await page.goto('https://danube-web.shop/')
const url = await page.$eval('img', (el) => el.src)
const response = await axios.get(url)
fs.writeFileSync('scraped-image.svg', response.data)
await browser.close()
})()
We are using axios to make a GET request against the source URL of the image. The response body will contain the image itself, which can be written to a file using fs.
Generating JSON from scraping
Once we start scraping more information, we might want to have it stored in a standard format for later use. Let’s gather the title, author and price from each book that appears on the home page of our test site:
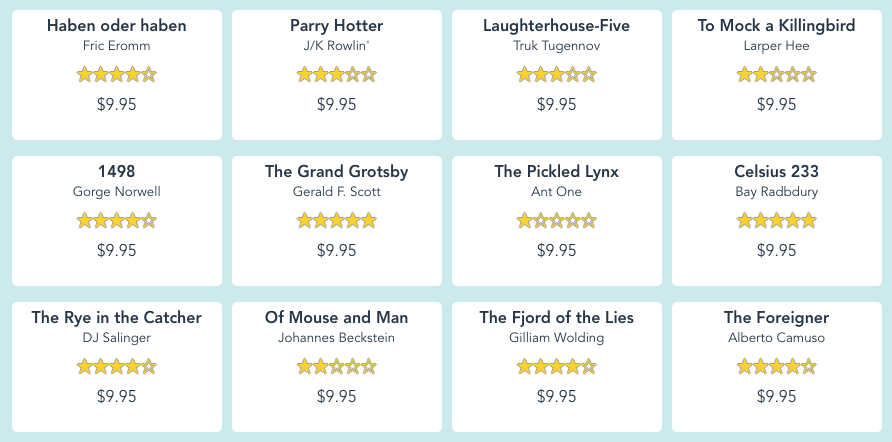
The code for that could look like this:
const { chromium } = require('playwright')
const fs = require('fs')
;(async () => {
const browser = await chromium.launch()
const page = await browser.newPage()
await page.goto('https://danube-web.shop/')
const content = await page.evaluate(() => {
const data = []
const books = document.querySelectorAll('.preview')
books.forEach((book) => {
const title = book.querySelector('.preview-title').innerText
const author = book.querySelector('.preview-author').innerText
const price = book.querySelector('.preview-price').innerText
data.push({
title,
author,
price
})
})
return data
})
const jsonData = JSON.stringify(content)
fs.writeFileSync('books.json', jsonData)
await browser.close()
})()
The resulting books.json file will look like the following:
[
{ "title": "Haben oder haben",
"author": "Fric Eromm",
"price": "$9.95"
},
{
"title": "Parry Hotter",
"author": "J/K Rowlin'",
"price": "$9.95"
},
{
"title": "Laughterhouse-Five",
"author": "Truk Tugennov",
"price": "$9.95"
},
{
"title": "To Mock a Killingbird",
"author": "Larper Hee",
"price": "$9.95"
},
...
]
All the above examples can be run as follows:
$ node scraping.js
Further reading
- Playwright’s official API reference on the topic
- An E2E example test asserting agains an element’s
innerText